When I was young I started playing around with 68000 assembly, I was absolutely obsessed with squeezing every last byte out of my code and optimising it as much as I could, spending hours to get that extra few bytes out of the assembled executable. I continued on that front as I started playing with C until a friend of mine said to me “Computers get faster each year, you shouldn’t spend so much time optimising”. The general gist of his argument was that you hit the point of diminishing returns, especially in the face of computers getting quicker and quicker.
At the time I remained sceptical and felt that it was just ‘giving up’. Many years later when I was working on some projects for IFL, when my time became precious, I remembered his words and finally subscribed to the philosophy of striking a balance between optimisation and time invested.
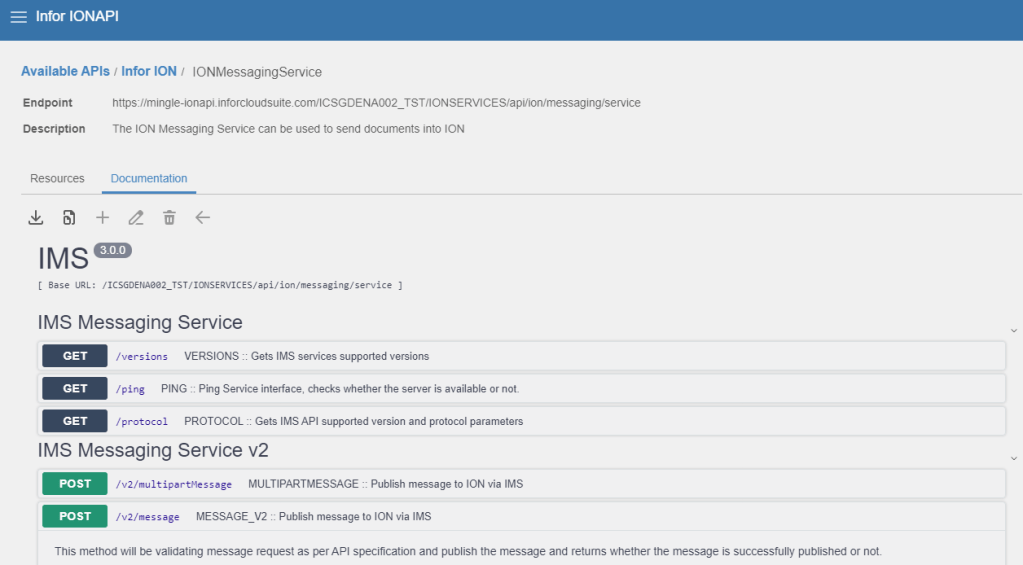
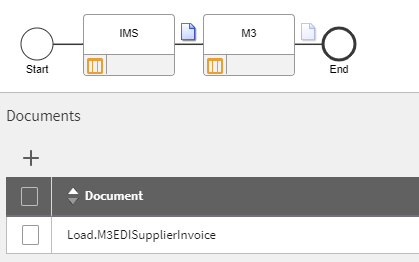
What does all this have to do with M3CE? Earlier in the year I was asked to help on a project where they had a MEC Map that was failing part way through processing. This wasn’t the first time I had come across this particular issue, however in this instance I was tasked with helping out at a more detailed level.
In this article, I won’t discuss the merits or flaws of the approach as we had some very narrow parameters to work within. For those if you, especially the veterans that have worked with MEC maps in the past, it is worth while checking the available KB articles and resources online about the differences and recommendations when working with MEC in M3CE – it is different and there are several gotchyas that I’ve seen trip up people in the past. Of-course, as M3CE develops, so do the best practices…
But on to the subject of the post. This MEC map, when it was originally developed was taking a whopping 16 odd hours to process an incoming file. I think that it got shelved for several months as other project tasks took priority, however when it was revisited the MEC map would just fail. When we started looking in to this, we noticed that the map was failing after 1 hour, infact, it was being terminated. The mapping would only succeed if we used a very small subset of the data which wasn’t a workable solution.
At that point in time, there was a hard-limit of how long a MEC map could run and that limit was 1 hour. The limit had been introduced after the original map had been written.
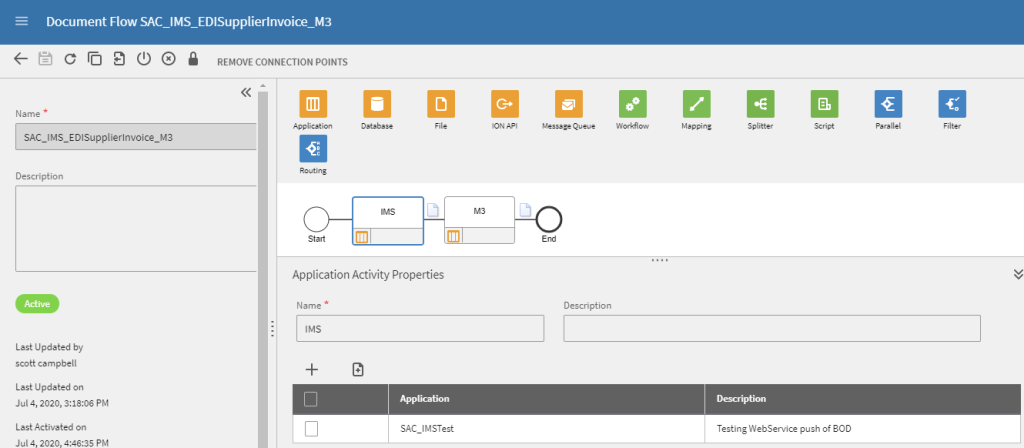
We ended up doing a bit of a deeper dive in to the map. As it turned out, the map would read a file that was passed to it from ION. This file would have several months worth of records for various customers that would be injested by MEC, accumulated and then written in to M3. The map was designed in a way that is fairly common, basically take a record, then process the record through various logic and then update M3, then go on to the next record. Each record processed would be treated discretely.
Because it needed to accumulate data, the map ended up writing records out to the CUGEX1 table – it was a clever solution and it also allowed that data to be leveraged for another task. (However we generally shouldn’t be using the CUGEX1 table for transactional data).
On top of this, for each line we would be making API calls to CMS100MI to retrieve some data and another API call for some other data. We’d then perform some calculations and eventually get around to updating M3 (this was with the current accumulated value, not the final accumulated value). Then we would need to go and clean up the CUGEX1 table which resulted in more API calls.
What this meant was that for a file that had a little under 50,000 records, we were making >200,000 API calls (it could have been more, I really started loosing interest in counting when we were getting in to such high numbers). What’s worse, we were using CMS100MI which is not the fastest, and it had a related table where we weren’t using the data. It was probably going to be used and then later the decision was made not to.
With a little bit of analysis of the file we were injesting, it became apparent that the accumulated data points would mean that we would essentially only need to write a few hundred times to M3 for the 50,000 odd records. With that in mind we knew that we didn’t need to store very much data so we ended up doing the following
- We created an in-memory array for our accumulated data points – this array would only have a few hundred records, so not too much memory
- We eliminated the CMS100MI API call, we were able to leverage a standard Get based called to fulfil this requirement.
- Where we could, we would cache the results of the Get calls in memory as we knew that the number of variations would be relatively small, so where we did a get for the item or the customer, we would cache the values
- Because we were using an in-memory array for the data points, we didn’t need to use CUGEX1 any more, so we didn’t need to populate it, nor clean it up at the end
In total, we reduced the number of API calls for the 50,000 line file to just a few hundred API calls, it also reduced the time it took to process the file to around 6 to 7 minutes. There were still other opportunities for optimisation too, but we of-course start to get to the point of diminishing returns and other project tasks started to take priority.
Closing Comments
In the single tenant world, we could afford to spend less time on optimisation and efficiency as our servers really spent a lot of time waiting for work. In a multi-tenant environment we are interacting with shared resources and we need to be conscious that we should be fairly efficient so we don’t consume compute capacity needlessly.
And I know many of you that I known me for a long time have heard me express disdain for MEC, but after working in M3CE for a couple of years I’ve really come to appreciate and like the technology. With that said, I think that it is really important when designing solutions that we use the right tools for the job, and MEC isn’t always that tool. With that in mind, here are some general philosophies I have – I cannot add enough emphasis, that these are general and there are probably scenarios that I’d consider would be exceptions – but in general
-
If a map is taking more than a few minutes, we should consider rethinking the design
- is MEC the right tool?
- Are we using the right APIs?
- does the process need to be redesigned.
If the map is taking more than 10 minutes, then I think it is really important to take a long hard look at what we are doing and seriously consider a different approach
- API calls are expensive, especially when we are making a lot of API calls. If we are submitting the same API call with the same data, many times, then investigate caching. This doesn’t apply to just MEC, I apply this philosophy to scripts, widgets etc (where practical). Of-course, we need to consider that caching consumes memory, so it may not be ideal for large volumes of data
- Large files – MEC isn’t really the ideal tool for extracting or consuming large volumes of data. If you are wanting to do that, consider other tools
I hope that this has been useful…happy MeCing… 🙂