
I have a fascination with graphs – in particular graphs that map things like performance and health.
Graphs are typically my number one go-to for troubleshooting…and I’m going to provide some anecdotes, as I know there are people in the past that have questioned what they see as an unhealthy preoccupation in gathering needless data. 🙂
Todays post will build upon my previous two posts around the Poormans M3 monitoring (https://potatoit.kiwi/2015/07/03/the-poormans-m3-monitoring-powershell-and-rest/ and https://potatoit.kiwi/2015/07/18/the-poormans-m3-monitoring-part-2-the-autojobs/) and we shall discuss a Linux virtual machine that I have built up which will monitor for down events in M3 and also provide long term trending graphs.
The scripts and access to the VM will follow later – given there have been some conversations around this recently, I thought I’d get the post out before I’ve finished all of the tweaks.
The Gathering of Needless and Trivial Data
As mentioned above, graphs tend to be my go-to for troubleshooting – they can immediately point you in the right direction of a problem, warn you of an impending problem, or reduce the probability of something you’re measuring being the issue.
But before we can do that, we need data. The time investment in getting this data can be hard to justify, and I’ve battle on many occasions to get buy-in from staff and managers about the importance of that data – even if it may not be used for a long period of time or ever. Typically, I ended up building my monitoring whenever I had a free few minutes.
So, below are a couple of anecdotes where having the data saved a lot of time and it helps to break up a rather dry article 🙂
It takes 30 minutes to run!
When we first installed MoveX, we settled on Crystal Reports as our reporting tool of choice. It’s got its warts but it did what we needed. We wrote a little .Net front end which would simplify a number of tasks and all was well in the world…until we started getting complaints saying “Report X is running really slow now, it takes 30 minutes to finish”. However whenever we would run it it would take in the order of 5 – 10 minutes. It’s a long time, yes, but a significant difference between that and 30 minutes.
Now I had already been bitten by the gathering needless and trivial data bug, so my little front end would log certain data to a database – this included who ran the report, the name and path of the report, the parameters and most importantly the start and stop time of the report generation. From this, I could say my sceptical staff that no, the report didn’t actually take 30 minutes to run, it was well less than 10. They didn’t believe me so I told them to time it. These conversations quickly stopped.
The purpose of collecting the data wasn’t to prove people wrong, it was to provide some absolutes. Peoples perception of time passing seems to warp considerably depending on just how frustrated they are, and in the past I had spent many hours chasing ghosts because people would say “it’s taking a long time to log in”, when the reality was, it was nothing had changed.
With the reports, I pre-empted the conversations. It meant that I wasn’t wasting time looking for vague problems but it also provided me with data on how the system was performing. With some quick SQL queries I could see if reports were starting to take longer so then I could look at justifying expenditure on new faster equipment. It also meant I could potentially identify problem reports that needed tweaking.
Why are these backups taking so long?
We had a DR site in another city – we would replicate our virtual machines from Christchurch to Auckland each night. Only deltas would sync so we could easily get away a 10meg pipe. Replication would typically be under a couple of hours. One day we had the time blow out significantly. A quick check of my ping statistics showed that ping times had gone from around 12ms to >18ms – I could see from my traffic graphs that this was happening even when there was nearly no traffic passing over the link.
And that’s where my troubleshooting stopped – I could see that we had increased latency which had a significant impact on our replication times. With graphs in hand I was able to shortcircuit many of the initial questions our provider would have had. They could see a clear indication that ping times had increased overnight and stayed at the higher values.
Eventually we discovered we had been bumped off onto a secondary data circuit as a new high capacity backbone circuit was provision. Once we were moved back, our ping times returned to normal as did our replication times.
The graph below shows the response times after they returned to normal (~11ms); an hourly, nice and granular breakdown of the ping times, below that the full day where we can see our ping times drop from 18ms back to ~11ms, and a weekly graph below that. It’s very quick and easy to glance at these graphs and identify that ‘normal’ was no-longer what we are experiencing.

It is worth pointing out that in the middle graph we can see that there are different coloured peaks representing packet loss. This can be perfectly normal. The graphs are to provide guidance. It’s very easy to end up chasing ghosts, so we always need to build a picture of what is normal and then determine if our normal is an acceptable state.
Proactive Capacity Planning and Troubleshooting
By having these trending graphs around our network, CPU, disk, I’ve typically been able to stay ahead of issues. I can spot a server whose CPU is pegged with a runaway process often before staff start complaining. Or I can see that our network traffic has started to increase and need additional capacity. I can even start making informed guestimates on our future requirements and plan long term.
If something doesn’t feel quite right – then I have many different graphs which can often provide some clues as to why things don’t feel right and point me in a path to start troubleshooting or reassure me that everything is actually normal.
Troubleshooting when you don’t know what normal is, is time consuming and frustrating.
M3 Monitoring and Trending
I’ve always had issues with trending and monitoring M3 to the degree that I’d like. I had ended up settling on monitoring CPU utilisation on our iSeries – I toyed with getting some disk stats but it ended up being more hassle than it was worth. But with the CPU utilisation graphs I would able to quickly pick up on stuck jobs, especially in the early v12 (5.2) sp10 days. I found that CPU was a really good indication of health, so left it at that.
Pre-grid I had also a Nagios script which would monitor the autojobs, but that got difficult to deal with once we got the grid and by that point it was pretty rare to end up with autojobs that were stuck or just stopped.
With physical access to the hardware I was quite comfortable. But now that M3 is hosted for us, I don’t have the same levels of control that I had previously – experience has shown that the hosting company doesn’t have the skills to interpret performance metrics – assuming they are keeping an eye on them.
So, I wanted to make sure that I was getting useful statistics and building up trending so I could accurately back up my claims when performance wasn’t up to scratch.
I wanted to do something that I could provide to other organisations – it would need to be fairly lightweight and easy to configure. I didn’t want Windows, as that now meant I couldn’t distribute a VM and if there were any additional packages required, it would be a pain.
So I ended up using SuSEStudio to generate a SuSE Linux VM with all of the packages required to run the scripts, it’s small requiring only a single vCPU, a few gig of RAM, 30gig of disk. I then use Perl (ugh, not loving it) to retrieve and process 3 different .xml files from M3 and the grid, along with another script that processes some data from a Windows SQL Server (sadly this requires a bit of tweaking for each environment). I use RRDTool to provide the data archives and to do the actual graphing of the data.
At the moment, the scripts will
- Save numerous performance counters from the /monitor and /grid/status and /grid/nodes
-
Parse the autojobs
- check that the correct number of autojobs are running (54 in the case of IFL)
- check for long running autojobs and send email notifications by simple counter of x number of consecutive checks above a threshold
- Check that all of the grid applications are in an online state, if not, send out an email
Email notifications are smartish, so it won’t spam you with alerts every check (1 minute for most), rather it will automatically suppress outgoing emails for a specified number of checks.
One of the key things is the graphs – we graph many counters so we can quickly and visually see if there is anything to be concerned about.
Graphs are just indicators, so I do have some unexpected behaviours from some of the counters – in particular things like Max Heap seems to change through the lifetime of some subsystems which isn’t what I expected. Also the RRDTool can normalise data, so it isn’t always ‘exact’ depending on a variety of factors. They are all about building a picture of your system.
We store >1 year of data in either 1 minute or 5 minute samples. Typically the graphs themselves are generated by another script and we can generate daily/weekly/monthly or annually. It is possible, but not terribly obvious how to generate graphs for any period within the 12 month dataset.
Checks are scheduled by cron jobs, so we can do things like generate our monthly/annual graphs less regularly. This is an example of my crontab file, monitorM3.pl checks the host ifbepd, it will query the host of both port 16008 (monitor) and 16001 (grid) and will read the monitor.cfg config file.

Given that there are some nice Rest APIs available in the grids, I will be looking at downloading the logs and parsing them with a perl script, so any warnings or errors for the processes get emailed daily for examination – but I need to play around with the parameters of the APIs to get what I want.
At the moment it has been tested on 13.2 and 13.3 – I did find that under 13.3 there was a subtle change in the /monitor file even though the files version number didn’t increment, so it is possible that there will be minor tweaks for different versions.
Below is a taste of what it can do so far…comments, thoughts, interest are more than welcome…
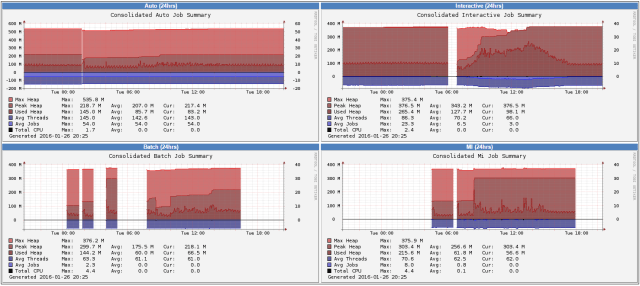
Subsystem Memory and Jobs
This provides some indications on how much of the heap each of the M3BE subsystems is using – when the Used Heap starts getting close to the Max, we should start investigating if we need more RAM.
Average Threads and Jobs gives us an indication of the threads and jobs in the subsystem aswell so we get a bit of a feel for the normal memory consumption.
The gaps in the graphs indicate when the subsystem was idle and was terminated.
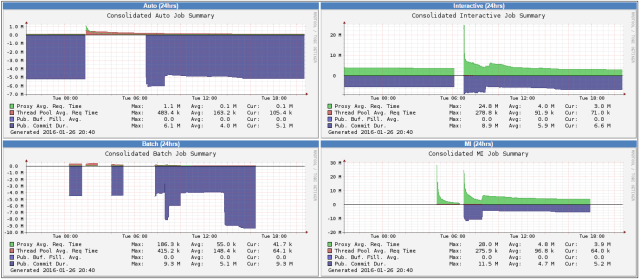
Subsystem Response Time Summary
The /monitor xml file has lots of very interesting fields – I’ve graphed some of the ones with interesting names but am struggling to get information on that the counters actually mean. Once I get a better idea, I’ll probably clean these up so they actually show some meaningful values 🙂
You’ll note negative values, I take some of the values and multiply them by -1 so we can get a better idea about the relationship between the different values, rather than having them lost in the noise.
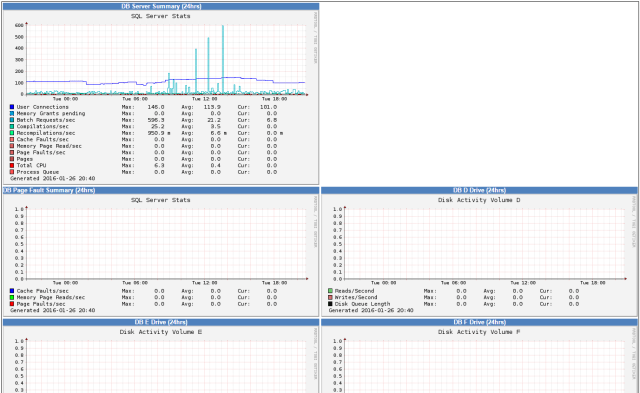
Node Memory & CPU
Like the subsystem memory, this shows us the memory used and the max heap, but of the grid applications. Again, if we start getting too high, we should look at increasing the memory available to the grid application. (this is only a small subset of the graphs, the script by default will extract the counters of all of the grid applications)

Server Summary
The data for this is generated from a powershell script that queries the WMI on a MS SQL Server that stores our M3 data. The powershell script ftps the data to our monitoring server, and our monitoring server parses the xml and stores the appropriate counters.
This is another graph which I’ll probably look at shuffling to be a bit more meaningful once I start to see trends. We also gather some disk I/O stats from the server – but they are pretty consistently boring and blank (probably a good thing)
General
I also go out and just graph all the counters that are recorded. (this is only a screenshot of a few)
So, you’ve made it to the bottom of the post, congratulations!
Is there any interest in this for others? The more interest shown means I’ll be more inclined to clean up a few annoying idiosyncrasies 🙂
Cheers,
Scott

Really good article, I would like to know,is there are any inbuilt reporting we can get from GRID level for check performance and troubleshooting….
Thanks,
Hi Roshan,
at the moment you can only get the current performance information – unfortunately no history data that can be used for trending which is part of the reason I built my own.
Cheers,
Scott
Great information here – really useful!
We have a prospect that is using M3 10.1 so has the Grid. Most of the elements they’re looking to monitor we can address by looking at the html or /monitor.xml. They’re really interested in looking to raise alerts for “job uptime and change” – any idea if this data is visble anywhere?
Thanks!
Ash.
Hi Ash,
under the /grid/nodes we have upTime which will tell you how long the nodes have been up. But that may not be granular enough.
I have a perl script which will fire an email off if an interactive job or autojob has been running for a long time with a certain level of change requests
(see around line 744 of the monitorM3.pl script)
The script has been used on 13.2 and 13.3 – I’ve only taken a brief look at 10.1, there may be some subtle changes to the layouts of the files but the script should work with only minor changes.
Cheers,
Scott
Awesome Scott! Thanks very much.
Ash.