
Recently I was asked about Disaster Recovery and M3. And though I haven’t really embarked on discovery of how companies handle M3 and DR I do hear people say they struggle with the changing of IP Addresses.
Which prompts a, huh? Why are we talking about changing IP Addresses?
This post is really to discuss the DR that I set up for IFL and because I had run in to this perceived need for changing IPs.
For us, it worked well, wasn’t too expensive to implement, and cheap to run. We were lucky in that warm standby DR was perfectly adequate, our M3 DB was only about 60gig and the business was prepared to accept the potential loss of ~24 hours of data.
Original DR 😦
Our original DR was based around restoring from backups on to equipment we sourced as quickly as possible. Given the long leadtimes with AS400s, we had an old AS400 sitting in a data center in the city and the expectation that it would be quick and easy to get x86 kit. If both our processing site and our old AS400 were destroyed then odds are the city has been flattened and we have bigger things to worry about.
As it turned out, after a major earthquake in February 2011, we had a situation where our primary site had a lot of damage but was operational (well, once we got generators and then grid power), and our DR AS400 was located in the CBD which was red-zoned with highly restricted access. The quake helped get approval for something a little more comprehensive.
What We Ended Up Doing
After having to spend large amounts of time in dealing with sick phone systems and firewalls, power cuts, ground shaking, stressed and tired staff and other such non-goodness, I wanted something that a single IT person could spin up quickly without needing too much thought. Geographical diversity was a major factor along with the implementation and on-going costs, the cheaper it was the more likely I could continue running it in perpetuity 🙂
We had adopted VMware pretty early on, so I was very comfortable with virtualisation and the only x86 stuff running bare metal was our backup server. I had been told about a product called Veeam which backed up VMware guests to a destination VMware server. Veeam would send the deltas so we didn’t need to spend huge amounts of money on WAN capacity. Because the guests were replicated as normal VMs, I could literally spin up the guest VMs in the DR site in the matter of minutes to test and revert them back to the original snapshot when finished.
So that covers the x86 servers – but we still have the AS400 which is what creates the biggest headache. We didn’t want expensive software and our database was only around 60gig so we decided to change our evening backups so after a tape backup was done, we would restore the backup to a temporary location, compress it and ftp it to the DR AS400, the DR AS400 would then restore the database. The benefit being we could prove our tape backups worked, and we would have a copy of our database that was a little over 24 hours old restored on another AS400. We had also considered detaching, compressing and sending the logs but it turned out we didn’t need to add that complexity.
Now this is where people started making things complicated designing the network – wanting to change IP addresses / wanting vlans and all-sorts of other goodness. Me, I like simple, I want to flick a switch and watch good stuff happen…
We were already going to be working with different subnets between our production and DR sites. As long as we make sure that servers that need to communicate between the Production and DR site are multi-homed and have appropriate static routes set up then routing provides isolation. This meant for the AS400s we needed to assign an additional IP at each site in a different subnet and a static route to ensure traffic going from one network came from the secondary IP.
In the diagram below – the green represents production, the orange DR. The production AS400 would ftp our compressed database to 192.168.10.16, packets would go from the DR AS400 to the production AS400s 192.168.11.16 address – this was required some static routes to get set up.
Traffic to the 192.168.1.x network at the primary site was local, so it would never be routed. At the DR site, there was no route set up to the 192.168.1.x network, servers with 192.168.1.x addresses at the DR site would never be routed outside of the DR network. The default route at the DR site went out to the internet.
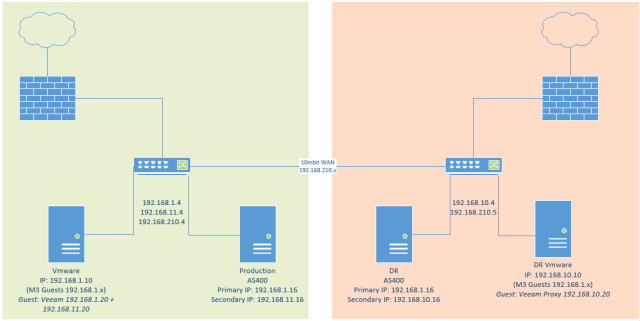
Ftping from 192.168.11.16 to 192.168.10.16
192.168.11.16 (PRD AS400) had a static route for 192.168.10.0/24 which pointed to 192.168.11.4
192.168.10.16 (DR AS400) had a static route for 192.168.11.0/24 which pointed to 192.168.10.4
Veeam, for our x86 replication involved a guest on by both the production and DR Vmware boxes. These guests were multihomed and had static routes just like the AS400s to allow traffic to pass between the networks, so traffic would pass from 192.168.11.20 to 192.168.10.20
Pulling it all together
It came together pretty smoothly, the biggest issue was the initial seeding of the guest VMs as the seeding process didn’t work as expected and took days (we only had a 10meg link between sites). Replication after that was very quick.
The most complex part was having to start the LCM Service on the AS400 from greenscreen – though that was pretty straight forward to document.
On a daily basis, we had a report that compared the record counts of specific key tables that tend to have daily transactions (eg. OSBSTD, FGLEDG) between the PRD and DR servers to confirm that the restores to the DR Server were working.
We needed some of our core servers to support M3 (LDAP Server, DNS etc), so we replicated them too (infact Veeam worked so well that I bought more disk and we ended up replicating everything each night). On a monthly basis we would do basic testing to ensure our plan stilled worked and we could log in and run programs. Quarterly, we would do more comprehensive tests and on an annual basis even more detailed tests.
The basic tests would take less than an hour from start to finish.
Shortcomings of the Solution
This particular solution wasn’t quite as elegant as I would have liked but I was confident that I could hand our recovery documentation over to a 3rd party and they could get us up and running.
These are the notable shortcomings…
Set Database Authority
I can’t recall if we needed to do this every time (I think it was only initially as we were building the solution) but if the M3BE didn’t start correctly we would check the database authorities, if they weren’t set we just needed to run the Set Database Authorities.
Starting the LCM Service Manually
We did have to start the LCM Service on the AS400 manually – we kept it shut down when not running up for testing. Greenscreen is pretty scary and foreign to many, but it was very easy to document this step.
Patching
The x86 servers weren’t an issue, as the guests were replicated in their patched state. However the AS400 file system was not replicated. We were fairly static from a M3 patching perspective at that point, but when we did have occasion to patch, it would be a case of copying the appropriate directories from the PRD IFS to the DR IFS. This was acceptable to us to do manually on the odd occasion it occurred.
Upgrades
Though we never did an upgrade when we were running this configuration, like patching from the AS400 perspective it created some issues which would require planning and manual discovery and testing.
DNS Resolution
We did have an issue with one of the grid applications not resolving DNS properly at the DR site after an update, I never tracked down the source of the problem but manually adding an entry in to the hosts file on the AS400 allowed us to work around the issue.
Closing Comments
I mentioned above that I wanted something easy that didn’t require too much thought. Though my design was a bit of a compromise between ease and cost, I made sure that I had a comprehensive document that walked through each step to bring the DR network up in painful detail. This document could be handed to anyone with the appropriate credentials and with little IT knowledge could bring the network up to a basic functioning state.
The complexity was due to the AS400, if we had been pure Windows (or mixed Windows/Linux) then Veeams replication would have eliminated pretty much all of the shortcomings.
DR situations are stressful, when multiple parts of your infrastructure have failed or are exhibiting aberrant behaviours, when your sleep cycle is constantly interrupted, when dealing with equally tired and stressed staff, the ability to make clear concise assessments and judgement calls gets difficult. Having a concise document which you can step through with minimal thought or that you can hand off to someone potentially in another location to handle is invaluable.
This was done with M3 10.1

Amazing Scott. You always have interesting projects, the resolve to implement them, and the willingness to share them. Thank you.
Thank you for your comments Thibaud, much appreciated.